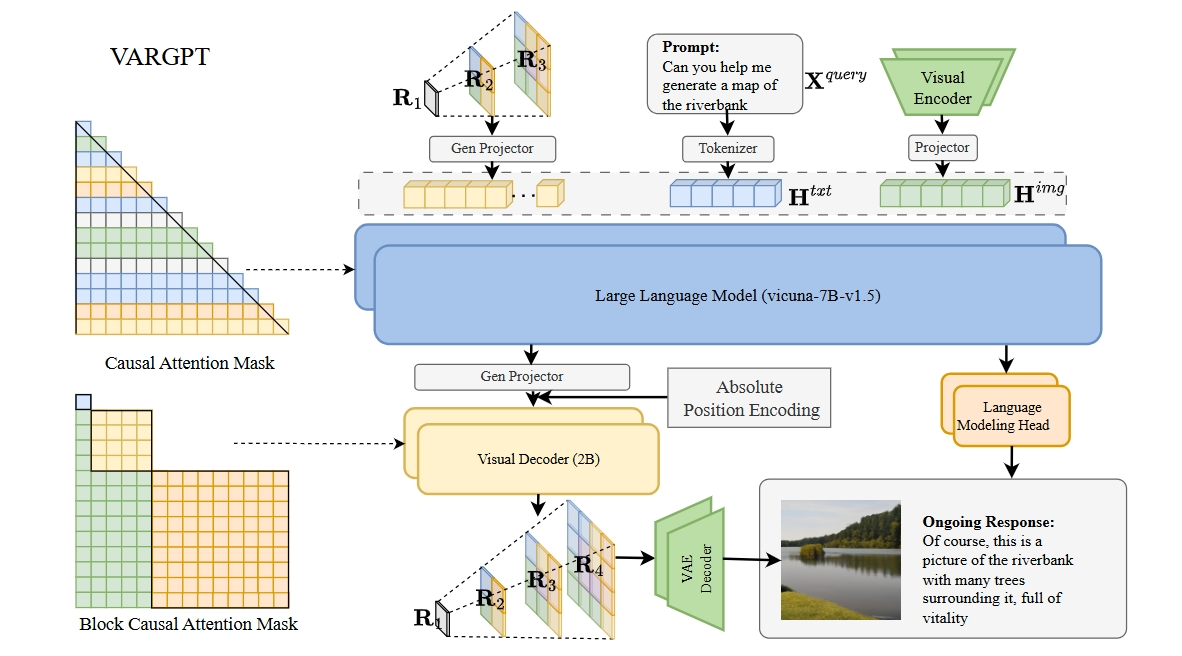
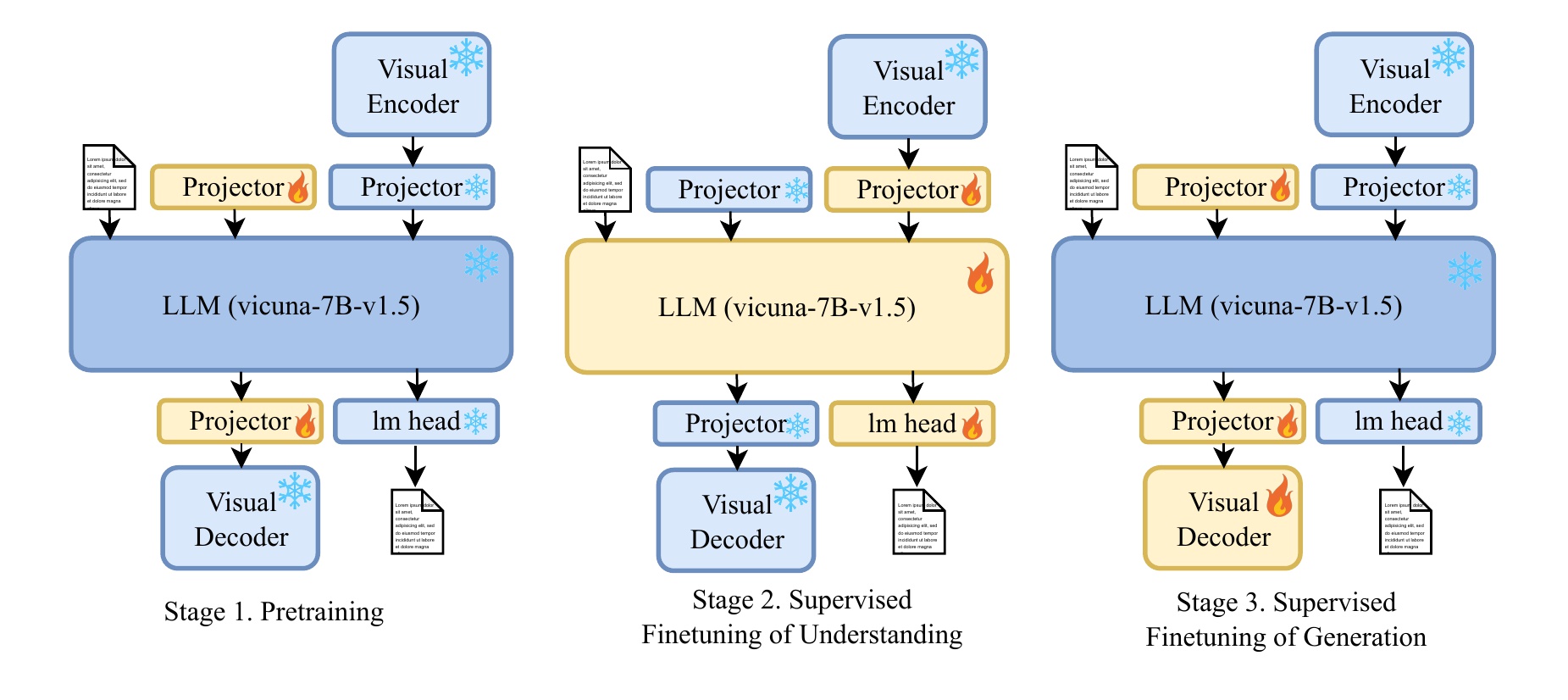
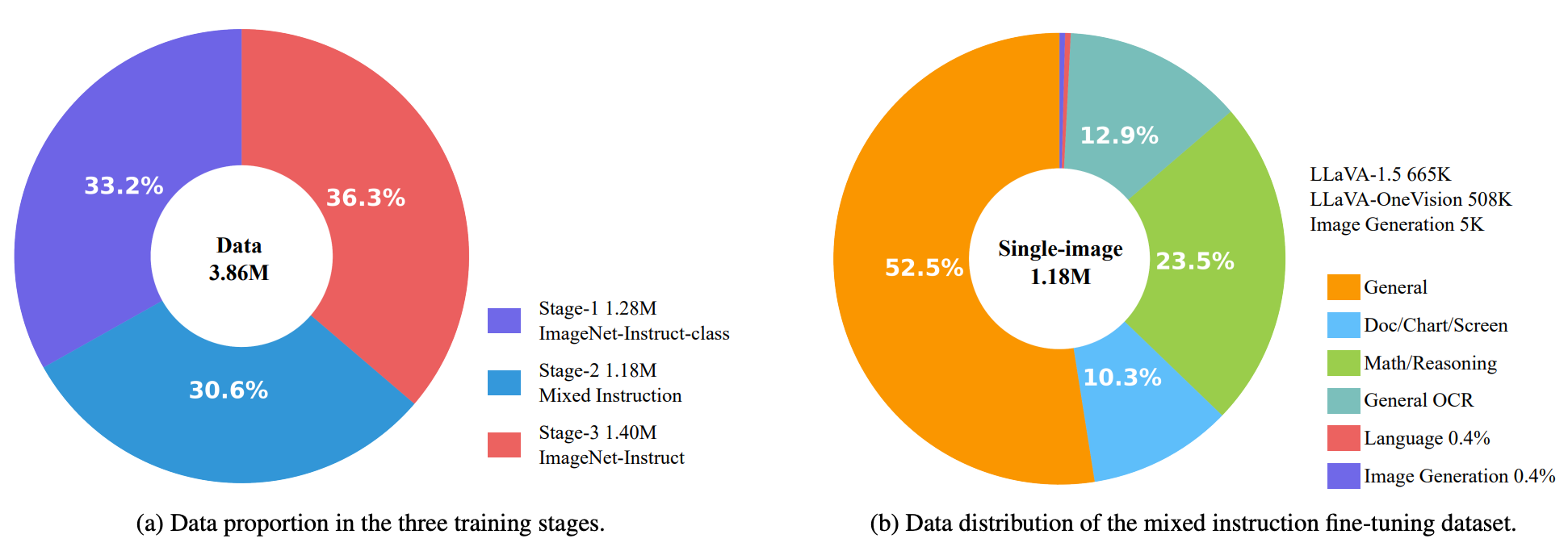
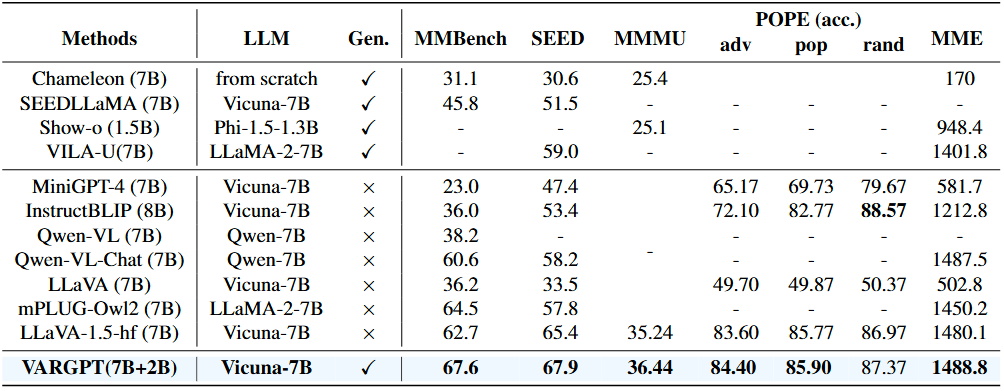
Abilities
Comparative analysis
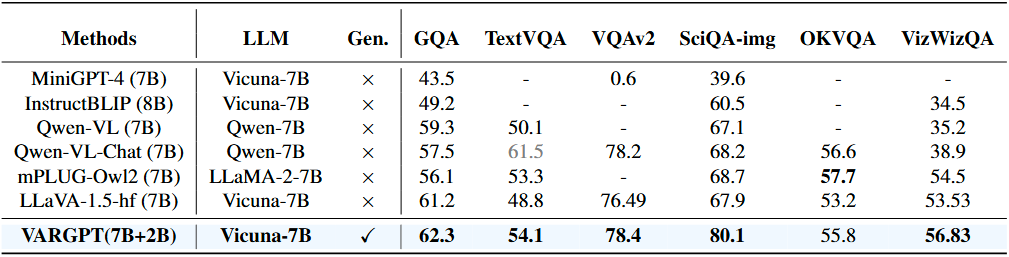
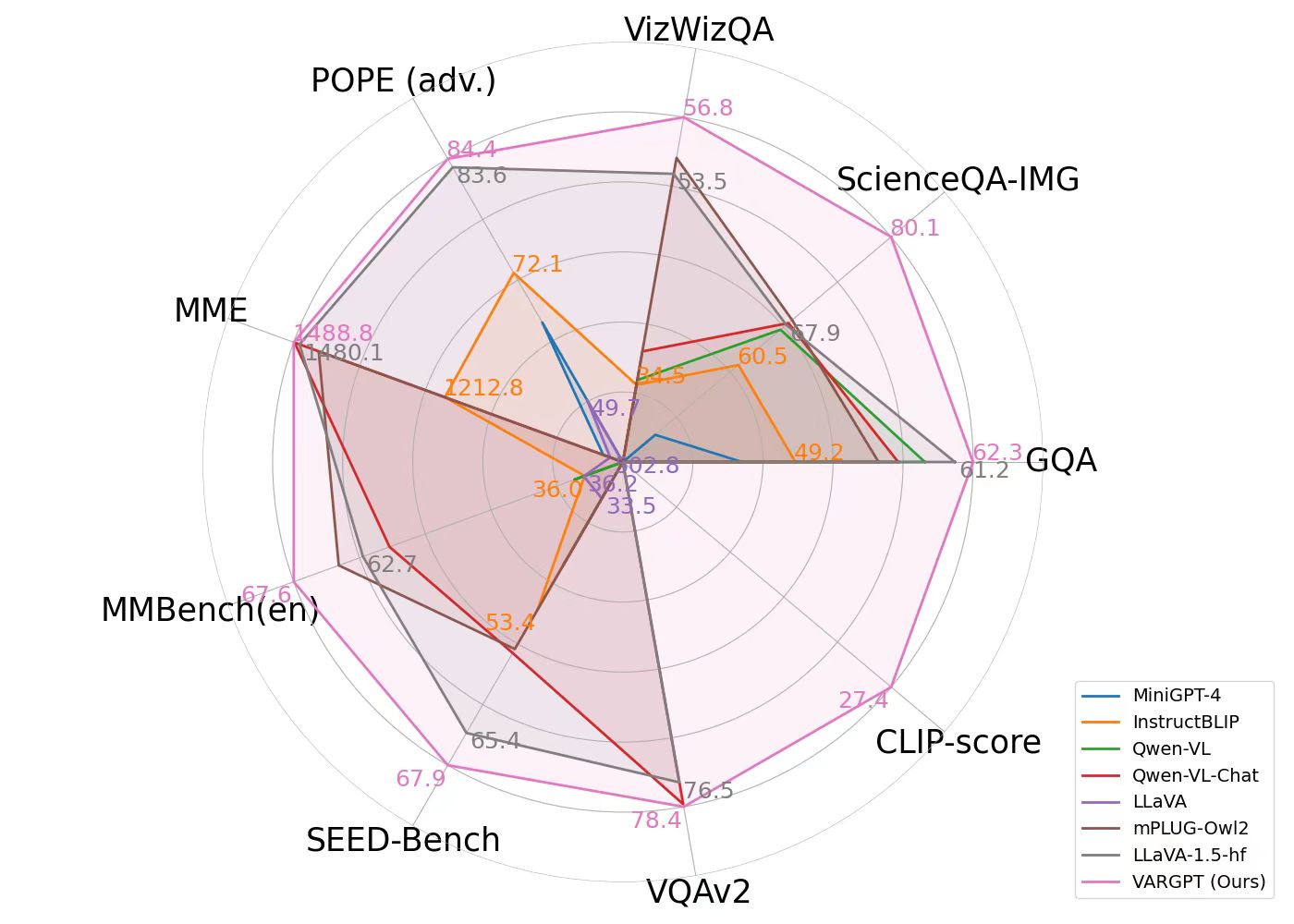
A comparative analysis of various MLLMs across multiple visual comprehension and generation benchmarks is presented. The CLIP-scores is employed as a text-to-image visual generation metric, while the remaining metrics are derived from standard visual question-answering benchmarks and multi-modal comprehension benchmarks. Notably, our VARGPT model demonstrates significant superiority over the compared baselines across all comprehension benchmarks. Furthermore, it exhibits exceptional instruction-to-image generation capabilities, thus enhancing its versatility and applicability in diverse visual-linguistic tasks.
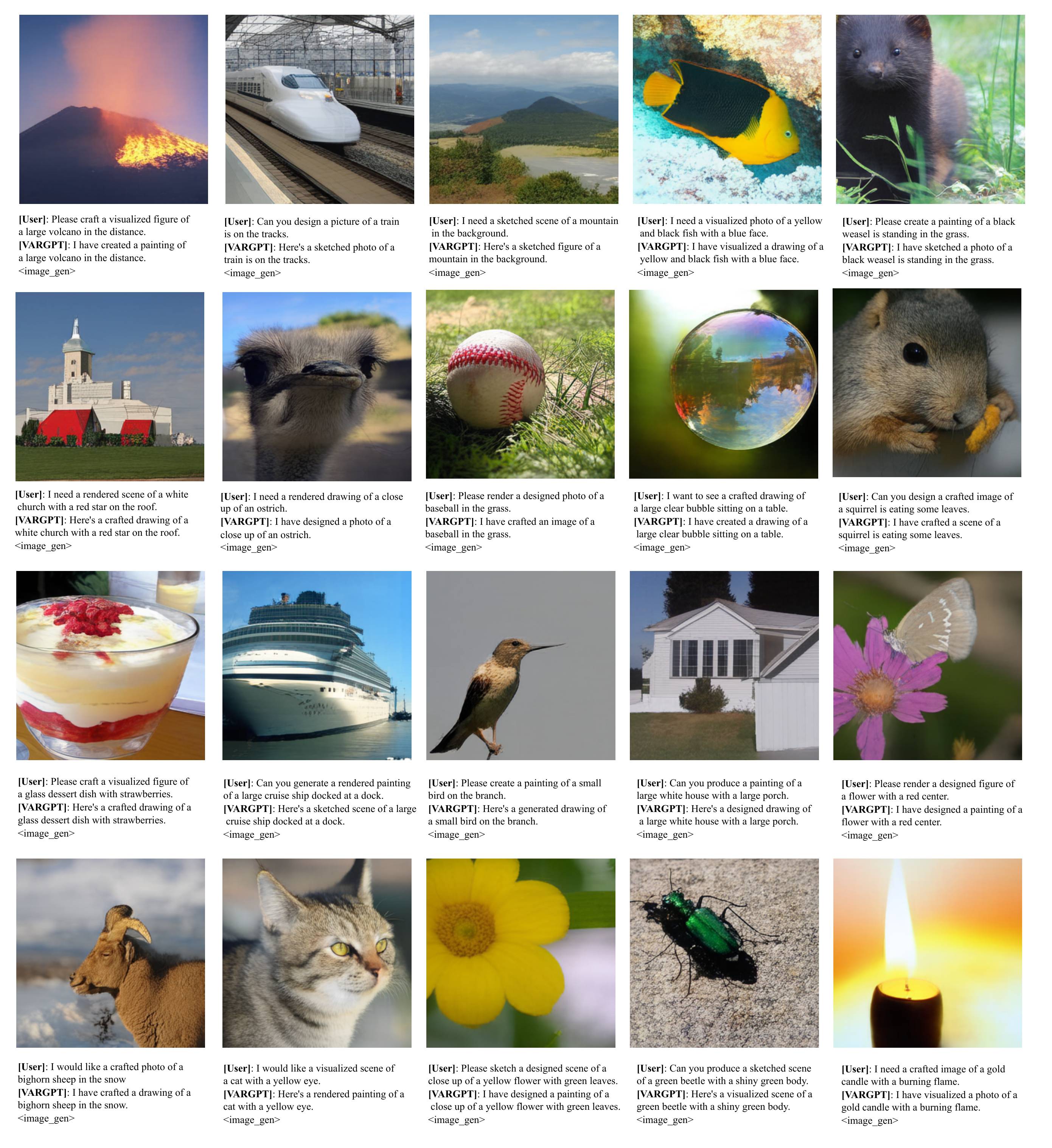
Generated samples
Some generated 256*256 samples by VARGPT trained on ImageNet. VARGPT supports text-and-image instructions from user and outputs both text-and-image mixed modal data simultaneously.